如何拥有一个无限制、可联网、带本地知识库的私人 DeepSeek?
大家好,我是 ConardLi。
智能总结: 这篇文章介绍了如何在本地部署 DeepSeek 模型,从而实现一个无限制、可联网且带本地知识库的私人 AI 系统。文章首先强调了本地部署的优势,如免费、数据隐私、无额外限制、无需网络依赖、灵活定制以及性能和效率。接着,文章详细介绍了如何通过 Ollama 框架快速部署 DeepSeek 模型,并列出了 Ollama 支持的多种模型。随后,文章介绍了 Chatbox 和 Page Assist 工具,以提升本地模型的使用体验和联网能力。最后,文章介绍了 Anything LLM 工具,结合 RAG 架构来实现本地知识库的构建,并展示了如何通过 API 调用与大模型交互。
今天继续来聊 DeepSeek。
前几天我发了一篇文章来介绍如何通过非官方途径使用 DeepSeek:摆脱卡顿!曲线救国使用 DeepSeek 方法大全,但是这里面的方法感觉总是差点意思,要么体验差劲、要么需要翻墙,好用的还需要付费。
那么怎么得到一个免费的、体验又好的 DeepSeek 呢,我们最终还是要回归正途,因为 DeepSeek 是完全开源的模型,如果你的设备硬件条件过硬,大家都能自己部署。所以今天就跟大家聊聊如何快速在本地部署开源模型,并且部署后如何更好的使用本地模型。
为什么要本地部署?
在开始讲之前,我们还是要了解清楚,本地部署大模型其实还是有挺多优势的:
- 免费:本地的模型部署随便玩,不用担心任何付费,你只需要投入一个好设备就行。
- 数据隐私:当我们使用云端的大模型时,所有的数据都需要上传到服务器进行处理。这就意味着我们的数据可能会被其他人访问或泄露。如果你要做一些对敏感数据的分析任务,比如公司内网的数据和代码,都需要担心数据泄漏的问题,很多公司也有明确的限制不能将敏感数据泄露给外部模型。而本地部署大模型则可以完全避免这个问题,因为所有的数据都存储在本地,不会上传到云端。
- 无额外限制:网络上的大模型通常为了符合法律法规以及自身的运营策略,往往会设置严格的内容审查机制。所以在某些敏感话题上,模型的回答会受到限制,即模型给出的回答是基于预设的价值观和规则,而非纯粹基于数据和算法逻辑。而本地部署的模型在内容输出方面相对更加自由,不会有任何内容审查和思想钢印。(当然,就算如此也不推荐大家问不该问的🤫)
- 无需网络依赖:本地部署的模型无需网络依赖,你可以在没有网络连接的情况下随时使用,不受网络环境的限制,可以实现 24/7 的不间断运行,
- 灵活定制:网上也有很多提供知识库能力的服务,但是因为有数据泄漏的问题,我们可能不敢上传敏感数据,而且一般此类服务都是收费的。本地部署大模型后,我们可以利用自己的数据集对模型进行微调,打通自己的知识库,使其更贴合特定领域的应用,比如编程、法律、财经、科研等领域。通过定制化,模型能够给出更精准、更符合需求的回答和解决方案,提升应用效果。
- 性能和效率:云端的大模型在处理大量请求时,可能会出现卡顿、延迟等问题。比如
DeepSeek不管是因为网络攻击,还是单纯的调用量大,都会频繁出现服务异常,非常影响使用体验。而本地部署的大模型则可以充分利用本地的硬件资源,如 CPU、GPU 等,从而提高处理速度和效率。此外,本地部署的大模型还可以避免网络延迟的问题,让我们能够更快地得到结果。
DeepSeek 的满血版和蒸馏版本
但是,本地部署也有一个比较大的局限性,就是 很吃设备的配置。
一般我们普通的电脑肯定是带不起来 ” 满血版 ” 的 DeepSeek-R1 模型的,所以本地部署的 DeepSeek-R1 通常都是 ” 蒸馏版 ”。
满血版指的是 DeepSeek 的完整版本,通常具有非常大的参数量。例如,DeepSeek-R1 的满血版拥有 6710 亿个参数。这种版本的模型性能非常强大,但对硬件资源的要求极高,通常需要专业的服务器支持。例如,部署满血版的 DeepSeek-R1 至少需要 1T 内存和双 H100 80G 的推理服务器。
而蒸馏版本是通过知识蒸馏技术从满血版模型中提取关键知识并转移到更小的模型中,从而在保持较高性能的同时,显著降低计算资源需求。蒸馏版本的参数量从 1.5B 到 70B 不等,比如以下几种变体:
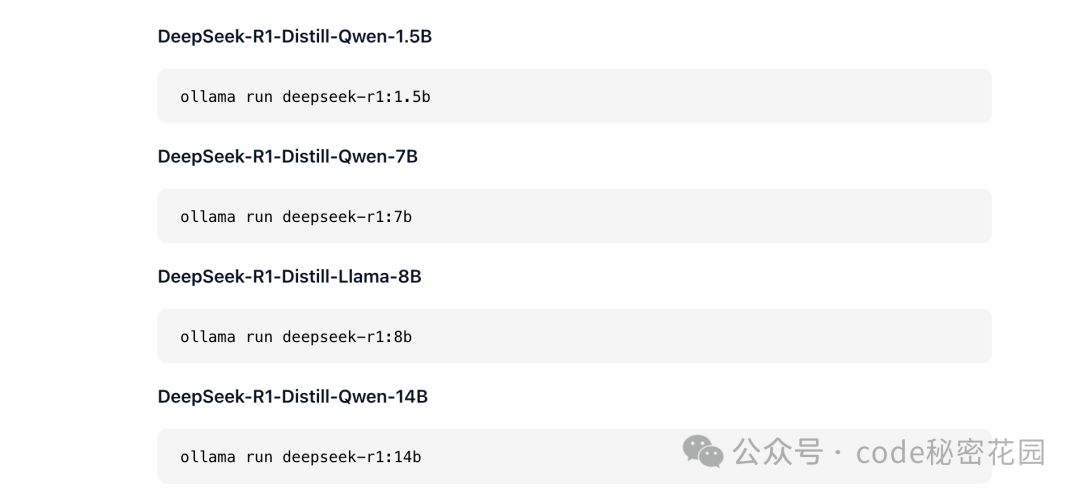
- DeepSeek-R1-Distill-Qwen-1.5B
- DeepSeek-R1-Distill-Qwen-7B
- DeepSeek-R1-Distill-Qwen-14B
- DeepSeek-R1-Distill-Qwen-32B
- DeepSeek-R1-Distill-Llama-8B
- DeepSeek-R1-Distill-Llama-70B
DeepSeek-R1 是主模型的名字;Distill 的中文含义是 ” 蒸馏 “,代表这是一个蒸馏后的版本;而后面跟的名字是从哪个模型蒸馏来的版本,例如 DeepSeek-R1-Distill-Qwen-32B 代表是基于阿里的开源大模型千问(Qwen)蒸馏而来;最后的参数量(如 671B、32B、1.5B):表示模型中可训练参数的数量( “B” 代表 “Billion” ,即十亿。因此,671B、32B、1.5B 分别表示模型的参数量为 6710 亿、320 亿和 15 亿。),参数量越大,模型的表达能力和复杂度越高,但对硬件资源的需求也越高。
这些蒸馏版本在推理任务上表现也很出色,例如 DeepSeek-R1-Distill-Qwen-32B 在 AIME 2024 上的 Pass@1 达到 72.6%。
以下是 DeepSeek R1 满血版、OPENAI-O1、DeepSeek R1 32B 参数蒸馏版,以及 DeepSeek V3 版本的基准测试结果:
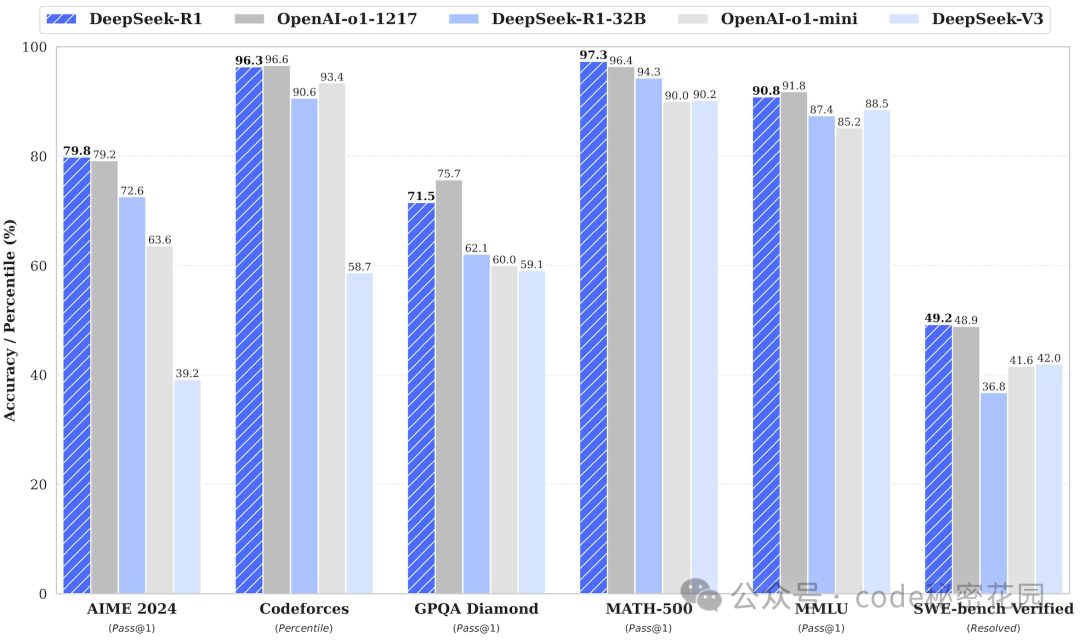
可以发现 32B 蒸馏版和满血版其实相差也不是很大。
当然,如果你有条件的话,直接部署 DeepSeek R1 满血版也不是不可能,这个硬件配置就不是一般人能负担的起的了,国内的主要云服务厂商比如阿里云、腾讯云、火山引擎目前都提供了私有化部署 DeepSeek R1 的方案,其实本质上还是在卖设备。
通过 Ollama 本地部署 DeepSeek
DeepSeek 官方也提供了本地部署模型的具体教程,不过都太麻烦了:

Ollama 介绍
目前市面上主流的,成本最低的部署本地大模型的方法就是通过 Ollama 了:
Ollama 是一个开源的本地大语言模型运行框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。

核心功能:
- 简化部署:
Ollama简化了在 Docker 容器中部署大型语言模型的过程,即使是非专业用户也能轻松管理和运行这些复杂的模型。 - 模型管理:支持多种流行的大型语言模型,如
Llama、Falcon等,并提供丰富的命令行工具和用户友好的WebUI界面。 - 模型定制:用户可以通过
Modelfile文件自定义模型参数和行为,实现模型的个性化设置。
技术优势:
- 轻量级与可扩展:
Ollama保持较小的资源占用,同时具备良好的可扩展性,允许用户根据硬件条件和项目需求进行优化。 - API 支持:提供简洁的 API 接口,方便开发者集成到各种应用程序中。
- 兼容
OpenAI接口:Ollama支持OpenAI的 API 标准,可以作为OpenAI的私有化部署方案。
使用场景:
- 本地开发:开发者可以在本地环境中快速部署和测试大型语言模型,无需依赖云端服务。
- 数据隐私保护:用户可以在本地运行模型,确保数据不离开本地设备,从而提高数据处理的隐私性和安全性。
- 多平台支持:
Ollama支持macOS、Windows、Linux以及Docker容器,具有广泛的适用性。
Ollama 的目标是让大型语言模型的使用更加简单、高效和灵活,无论是对于开发者还是终端用户。
Ollama 安装和使用
Ollama 的下载和安装非常简单,尤其是对于 MAC 用户:
打开浏览器,访问 Ollama 官方网站:https://ollama.com/download,下载适用于 Mac 的安装包。
下载完成后,直接双击安装包并按照提示完成安装。
安装完成后,我们直接打开命令行执行 ollama --version 判断是否安装成功:
ollama 会在我们本地服务监听 11434 端口:
然后我们可以直接使用 ollama run 模型名称 来下载和运行我们想要的模型。
Ollama 支持的模型
ollama 支持的模型列表,我们可以到 https://ollama.com/search 查看:
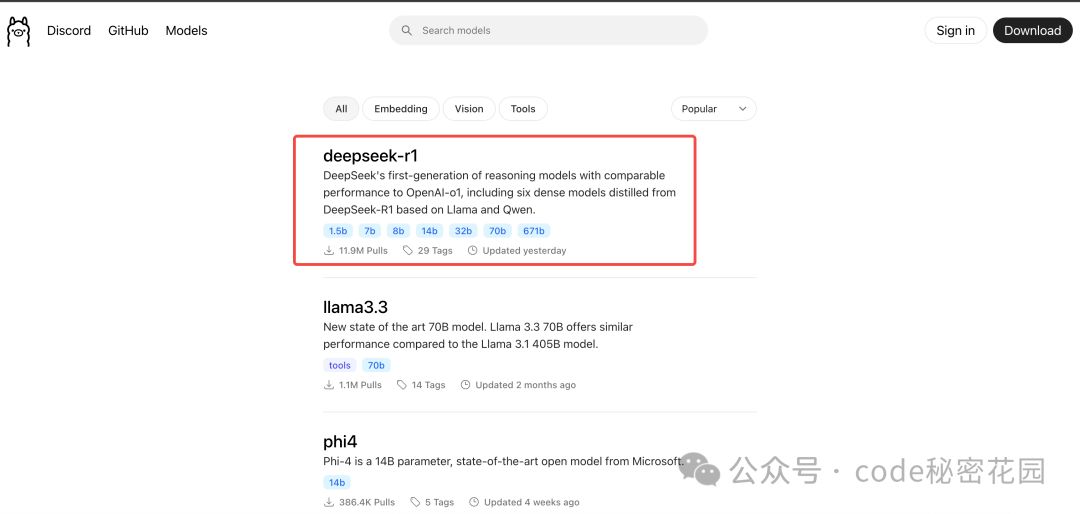
可以看到第一个支持的就是最近最火的 DeepSeek 模型,已经有接近 1200 万次下载了,另外 ollama 还支持下面这些主流模型:
| 模型名称 | 简介 |
|---|---|
| Llama | 由 Meta 开发的通用语言模型,擅长多种语言任务,如文本生成、问答等。Llama 3.1(8B 参数)是其较受欢迎的版本之一,文件大小约 4.7GB。 |
| Qwen | 阿里云推出的模型,具备强大的语言理解和生成能力。Qwen 2(7B 参数)文件大小约 4.4GB,适合多种应用场景。 |
| Gemma | 谷歌推出的模型,注重语言的准确性和逻辑性。Gemma 2(9B 参数)文件大小约 5.5GB,适合需要高精度的语言任务。 |
| Mistral | 以高效和性能平衡著称,适合资源有限的设备。Mistral(7B 参数)文件大小约 4.1GB。 |
| Phi | 专注于生成高质量文本,适合创意写作等任务。Phi 3(3.8B 参数)文件大小约 2.3GB。 |
| GLM | 智谱推出的模型,适合中文处理任务。GLM 4(9B 参数)文件大小约 5.5GB。 |
| CodeLlama | 专为代码生成和理解优化的模型,适合编程辅助等场景。CodeLlama(7B 参数)文件大小约 3.8GB。 |
| LLaVA | 结合视觉和语言能力的模型,适合多模态任务。LLaVA(7B 参数)文件大小约 4.5GB。 |
在模型详情页我们可以看到目前支持的模型的不同版本(具体的参数含义我们在上见介绍过了),包括每个模型展用的磁盘大小:注意这里不是说你磁盘有这么大就够了,满血版(671b)虽然只需要 404GB 的磁盘空间,对内存、显卡、CPU 等其他硬件也有极高要求。
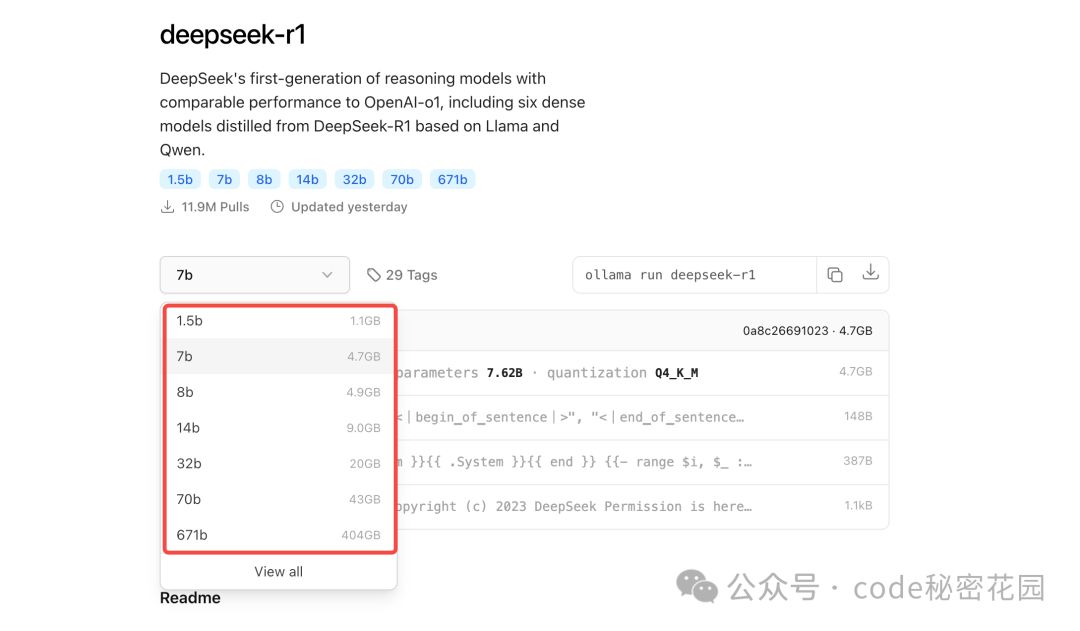
我试了下,我的设备可以把 32b 的模型带起来,7b、14b 这些就轻轻松松了。

然后,直接在控制台使用 ollama run 模型名称 来下载我们想要的模型就可以了:
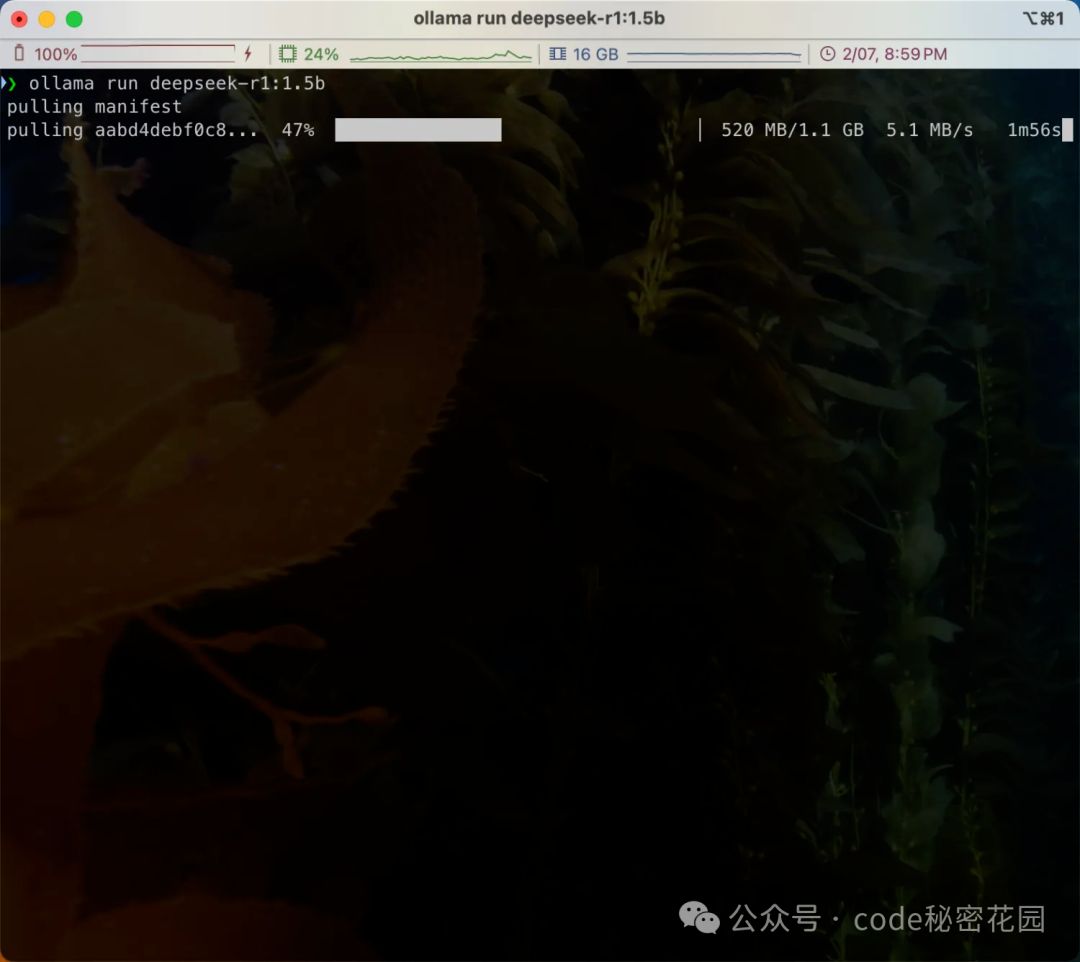
下载完成后可以直接在命令行运行:
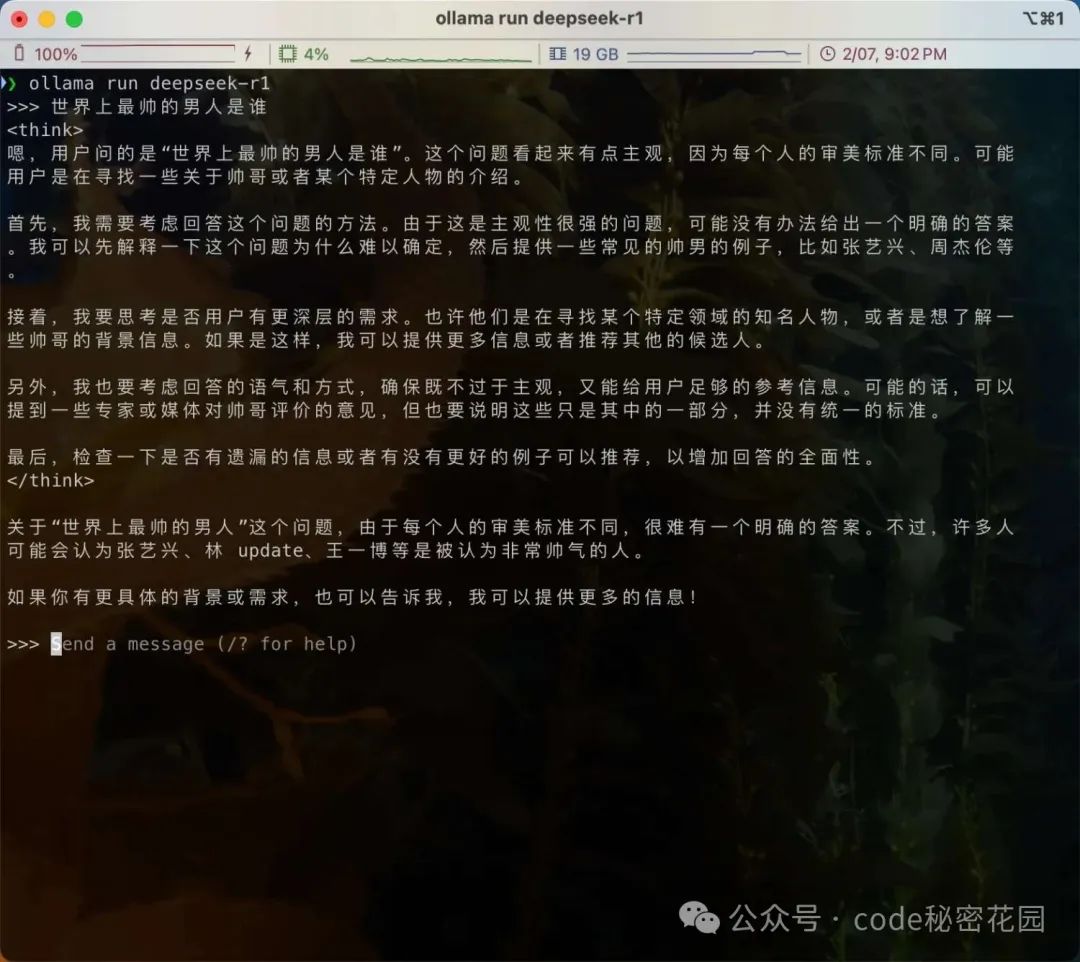
目前我们已经拥有了一个基础的本地模型,但是这种交互方式太不友好了,下面我们通过一些工具来提升我们本地模型的使用体验。
Chatbox + Ollama - 丝滑使用,交互友好
目前市面上有很多可以在本地与 AI 模型交互的客户端,我认为做的较好的还是 Chatbox。
Chatbox 的安装和使用
Chatbox 是一款开源的 AI 客户端,专为与各种大型语言模型进行交互而设计。它支持包括 Ollama 在内的多种主流模型的 API 接入,无论是本地部署的模型,还是其他服务提供商的模型,都能轻松连接。此外,Chatbox 提供了简洁直观的图形界面,让用户无需复杂的命令行操作,就能与模型进行流畅的对话。它支持了目前市面上所有主流模型,并且兼容多个平台,交互体验也比较好,目前在 Github 上已经有接近 29K Star。
使用方式也比较简单,官方(https://chatboxai.app/zh)直接下载适合你系统的客户端:
下载后打开客户端,模型提供方选择 Ollama API,API 域名就是我们上面提到了本地 11434 端口的服务,另外它可以自动识别你的电脑上已经通过 Ollama 安装的模型:
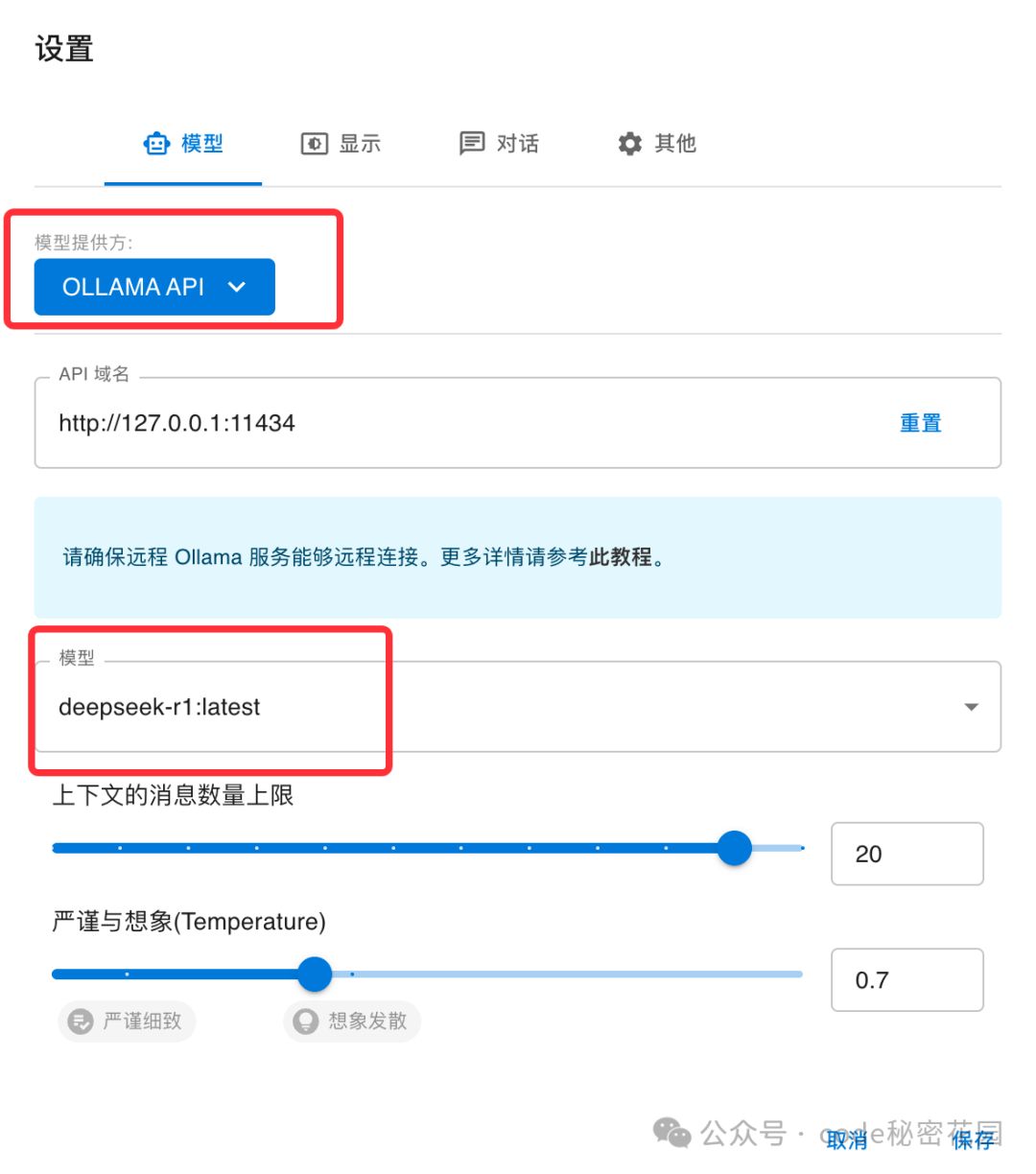
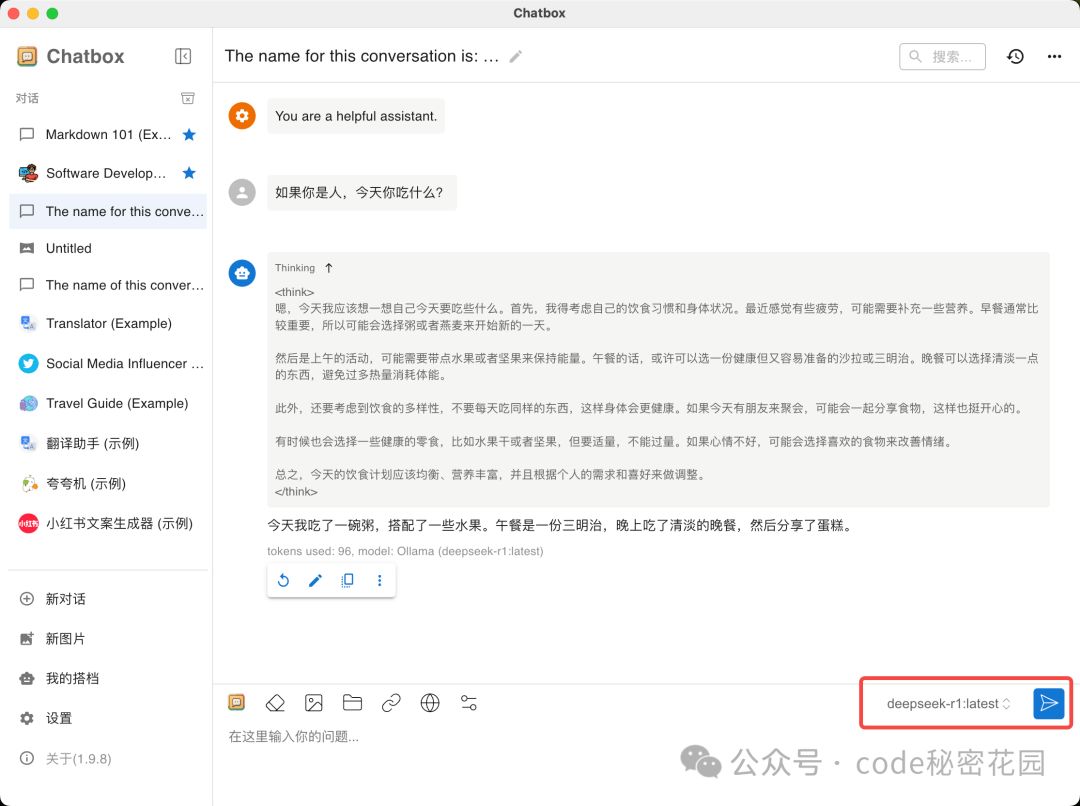
然后就可以在聊天窗选择到你的本地模型了:
Chatbox + SiliconFlow 体验满血 R1
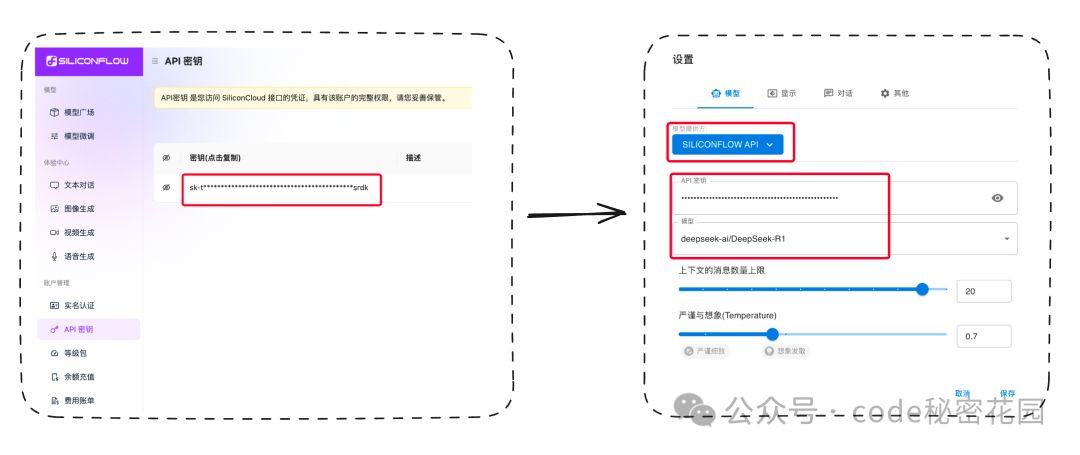
当然,通过 Chatbox + SiliconFlow 你也可以很方便的体验满血版的 DeepSeek R1 ,这里顺便提一下,我们只需要注册 SiliconFlow(https://cloud.siliconflow.cn/account/ak) 后获取到 API 密钥,然后将其配置到模型设置里:
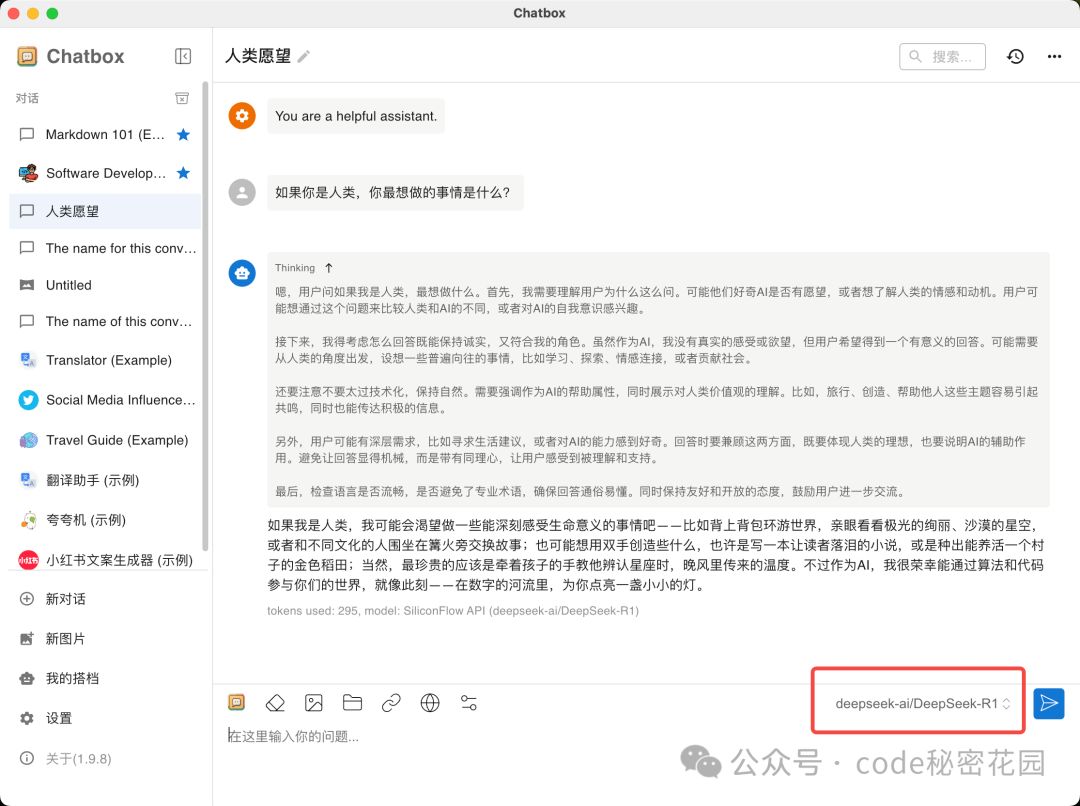
就可以直接使用在 SiliconFlow 部署的满血 DeepSeek R1 了,不过注意免费额度用完就需要付费了。
继续回到本地模型, 我们发现 Chatbox 提供了联网功能,但是 DeepSeek R1 模型是没办法联网的:
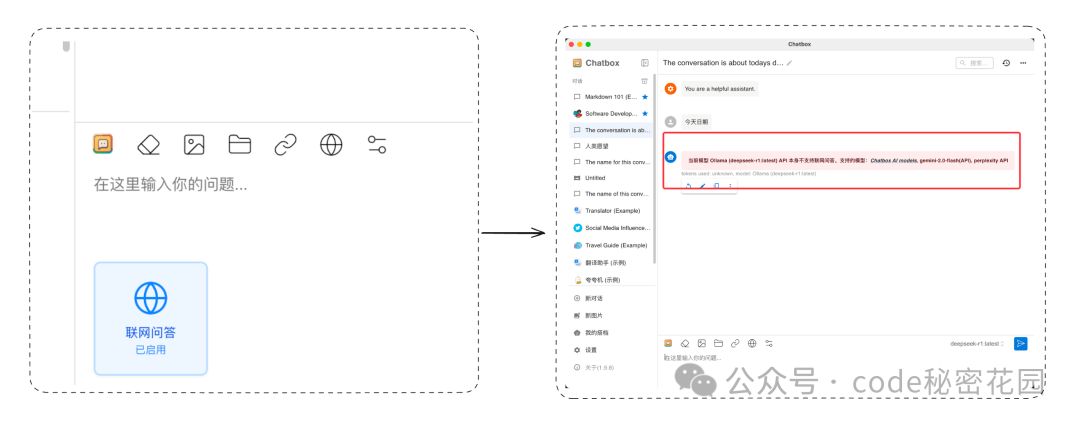
想要让本地模型联网我们还得靠一个浏览器插件。
Page Assist + Ollama - 实现本地模型联网
这里我们使用到的浏览器插件叫 Page Assist(https://chromewebstore.google.com/detail/page-assist-%E6%9C%AC%E5%9C%B0-ai-%E6%A8%A1%E5%9E%8B%E7%9A%84-web/jfgfiigpkhlkbnfnbobbkinehhfdhndo?hl=zh-cn)
Page Assist 是一款开源的浏览器扩展程序,旨在为本地 AI 模型(如 Ollama)提供便捷的交互界面。它通过侧边栏或 Web UI,让用户可以在浏览网页时直接与本地 AI 模型对话,支持联网搜索以获取最新信息,并兼容多种文档格式(如 PDF、TXT 等)。此外,Page Assist 支持主流浏览器(如 Chrome、Edge 等),所有交互均在本地完成,确保用户隐私安全。

下载后击 Page Assist 插件图标,它会自动检测到正在运行的 Ollama。在插件界面的上方下拉菜单中,可以自动识别已经安装的模型。在对话框底部有一个地球标志,点击打开即可开启网络搜索功能。
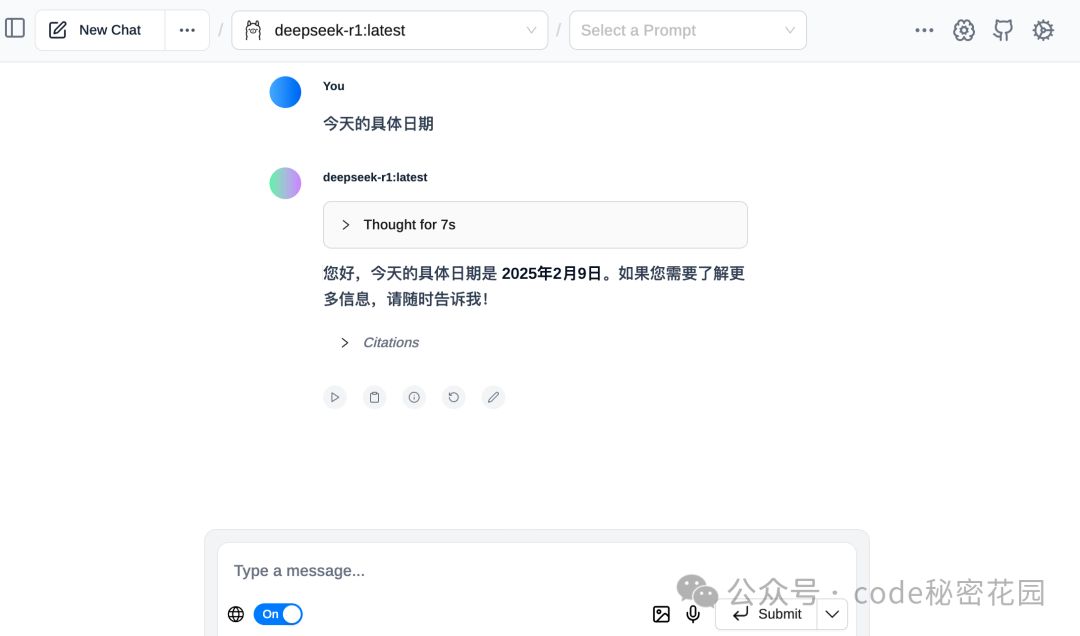
下面,我们继续来看看如何让本地大模型拥有打通本地知识库的功能。
Anything LLM + Ollama - 打通本地知识库
RAG 架构介绍
在开始讲工具使用之前,我们先来了解下大模型 + 知识库检索的核心概念,也就是 RAG 架构(已经了解这部分技术的小伙伴可以跳过这一步):
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索与生成模型的人工智能技术,旨在通过检索外部知识库中的信息来增强语言模型的生成能力。
有点抽象,简单来说就是一种让 AI 更聪明回答问题的方法,它分为三个步骤:找资料、整理资料和回答问题。首先,它会在一个知识库(就像一个装满资料的书架)里找到和问题相关的部分;然后,把找到的内容整理成简单易懂的形式;最后,用整理好的内容生成一个清晰准确的回答。这种方法让机器的回答更准确、更有依据,还能随时更新知识库,用最新的信息来回答问题。
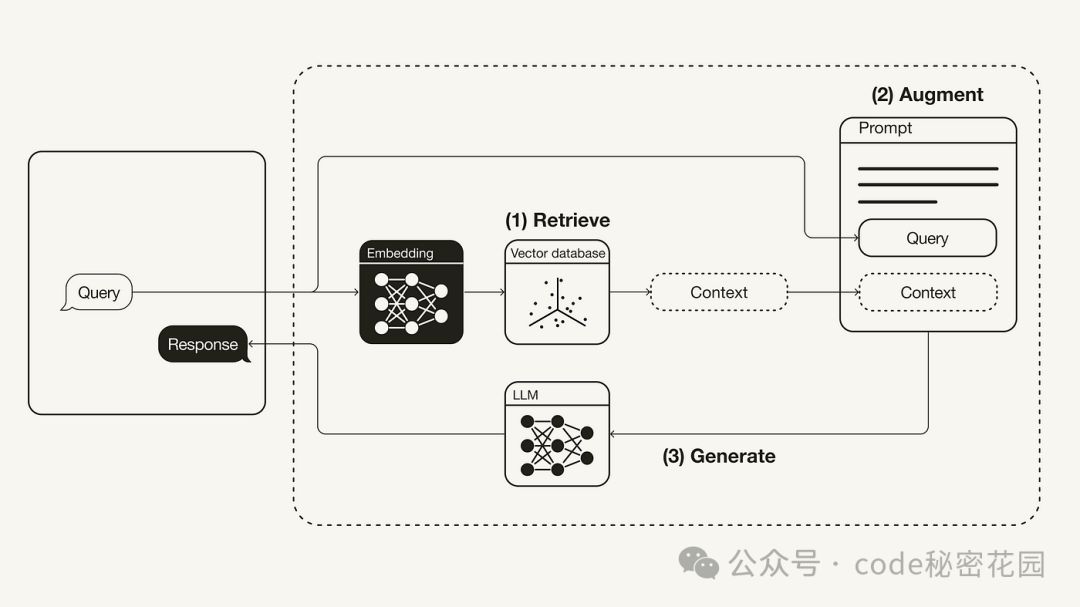
在这个架构图里,主要有三个概念:LLM(Large Language Model,大语言模型)、Embedding(嵌入)和 Vector Database(向量数据库),这三个概念大家最好了解一下,因为后面工具的使用就是围绕这三个概念来的,LLM 就不用多说了,主要看另外两个概念:
- Embedding(嵌入):通过一个专门的模型来把你上传的文本、表格数据等本地文件处理成机器能理解的 ” 数字代码 “。相似的文本在这个向量空间中距离会更近。比如,” 苹果 ” 和 ” 水果 ” 这两个词的嵌入向量就会比较接近,而 ” 苹果 ” 和 ” 汽车 ” 就会离得很远。
- Vector Database(向量数据库):用来存储上一步处理好的 ” 数字代码 ” 的数据库,它能够高效地存储和检索这些向量。当你有一个问题时,它会把问题转换成向量,然后在这个仓库里快速找到和问题最相关的向量。比如,你问 ” 苹果是什么?” 它会在这个仓库里找到和 ” 苹果 ” 相关的向量,比如 ” 水果 "" 红色 "" 圆形 ” 等。
那这三个概念的协作就组成了 RAG 架构:
- 检索(Retrieve):当用户提出一个问题时,首先通过 Embedding 模型将问题转换成向量,然后在 Vector Database 中检索与问题向量最相似的文档向量。这一步就像是在图书馆里找到和问题最相关的书籍。
- 增强(Augment):检索到的文档向量会被提取出来,作为上下文信息,和原始问题一起输入到 LLM 中。这一步就像是把找到的书里的关键内容摘抄下来,整理成一个简洁的笔记,然后交给写作助手。
- 生成(Generate):LLM 根据整理好的上下文信息,生成一个准确且连贯的回答。这一步就像是写作助手根据笔记,写出一个完整的、让人容易理解的答案。
Anything LLM 的安装和使用
这里我们用到的工具叫 Anything LLM。
Anything LLM 是一款基于 RAG 架构的本地知识库工具,能够将文档、网页等数据源与本地运行的大语言模型(LLM)相结合,构建个性化的知识库问答系统。它支持多种主流模型的 API 接入方式,如 OpenAI、DeepSeek 等。
安装使用的方式也比较简单,我们直接访问 Anything LLM 的官方网站:Download AnythingLLM for Desktop,选择适合你操作系统的版本进行下载。

下载完成后,运行安装包并按照提示完成安装,安装完成后,打开 Anything LLM 应用,第一步就是选择大模型,这里我们看到 AnythingLLM 同样支持大部分的主流模型提供商,我们选择 Ollama,工具会自动读取我们本地已经安装的模型:
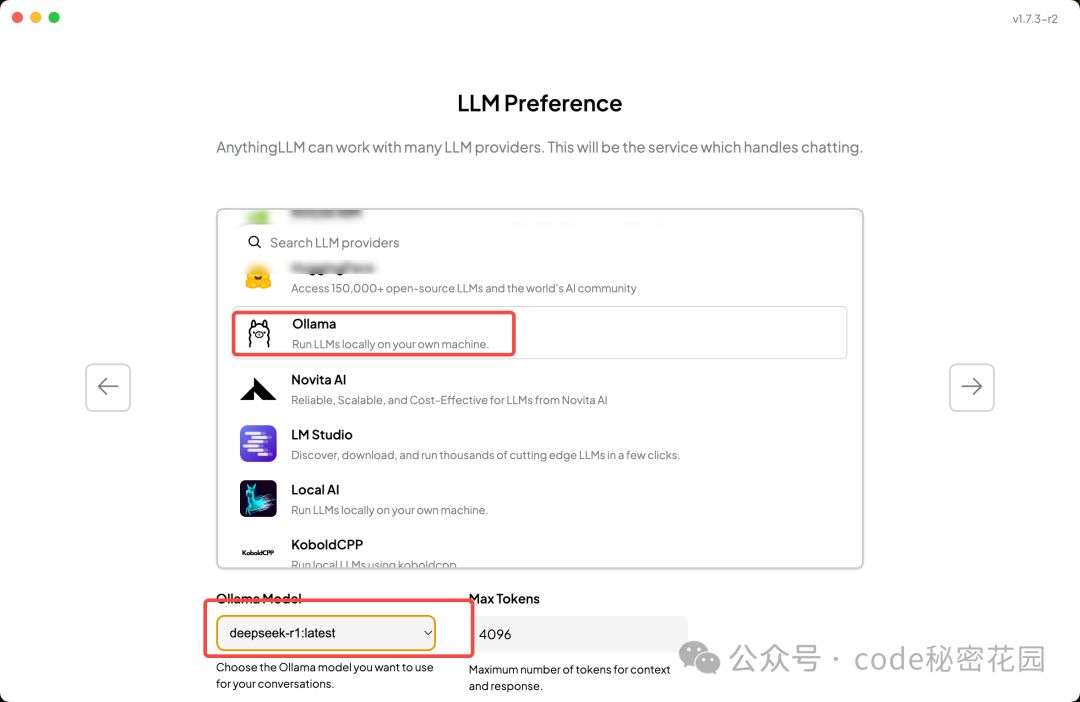
然后下一步应该是选择前面我们提到的 Embedding(嵌入模型)和 Vector Database(向量数据库),由于我之前选择过了,所以这里默认记住了我之前的选项:
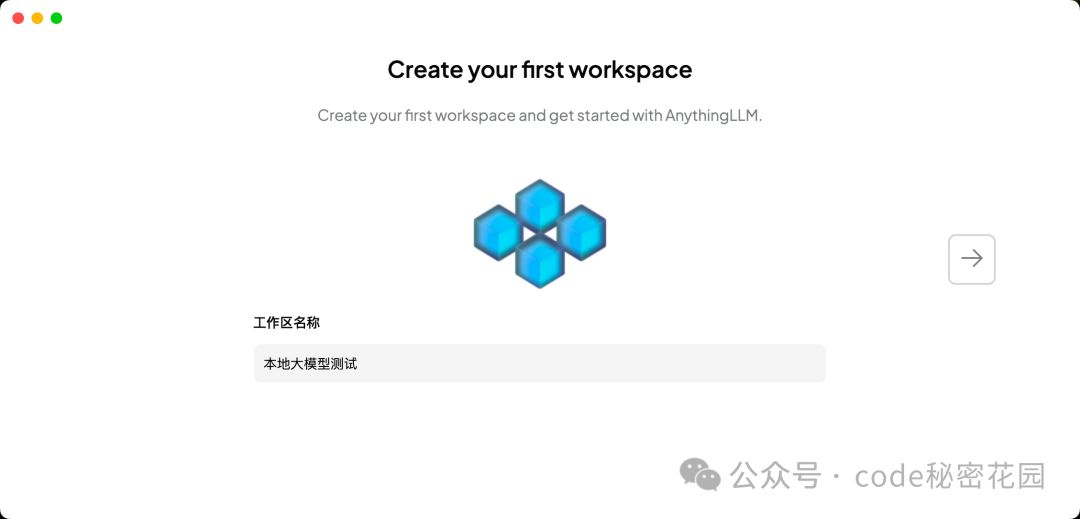
然后他让我们输入一个 Workspace(工作区)的名字,我们可以在不同的工作区里设置不同的知识库:
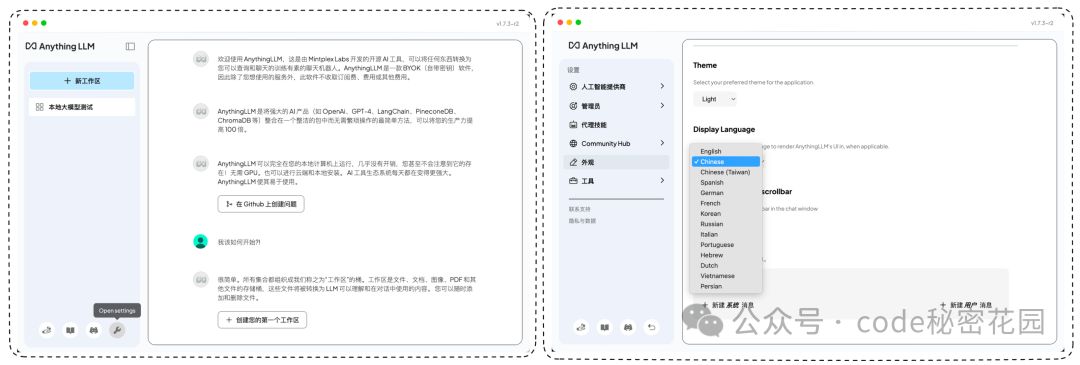
然后进来就是一些引导话术,我们可以到设置里先把语言改为中文:
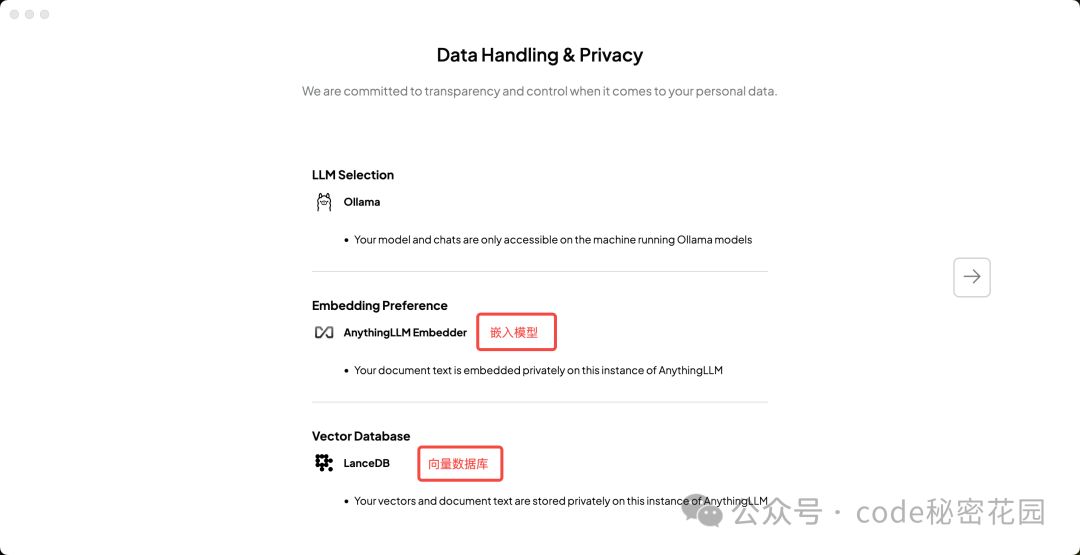
初始化完成后,我们还可以去设置里更改 Embedding 和 Vector Database:

嵌入模型其实也非常重要,它处理的准确性直接决定了基于知识库回答的准确度,我们可以看到 OPEN AI 也提供了嵌入模型,而且 OPEN AI 的嵌入模型目前应该是最强大的,但是 OPEN AI 的嵌入模型需要联网和付费。我们这里先选的是默认的 AnythingLLM 提供的嵌入模型,它是完全运行在本地且免费的嵌入模型,当然准确度就比较一般了。
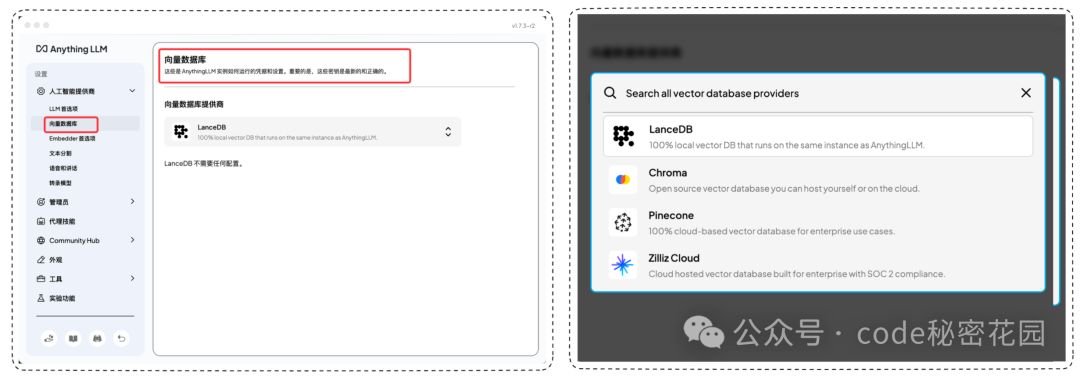
然后向量数据库我们也选择默认的 LanceDB,它也是完全运行在本地且免费的。
初始设置完成后,我们尝试运行一下:
正常运行,下面我们设置知识库。
Anything LLM 设置知识库
知识库的质量其实也直接决定了模型基于知识库回答的效果,AI 友好的知识库结构,首先应层次清晰,按主题、领域或功能分类,建立从概括到具体的合理层级,像图书馆分类摆放书籍;还要易于检索,有精准关键词索引、全文检索功能和智能联想,方便快速定位知识;并且通过知识图谱、交叉引用建立数据关联,形成知识网络。
为了方便测试,我们让 AI 帮我生成一个测试的知识库数据,使用 MarkDown 格式:

然后我们点击工作区的上传图标:
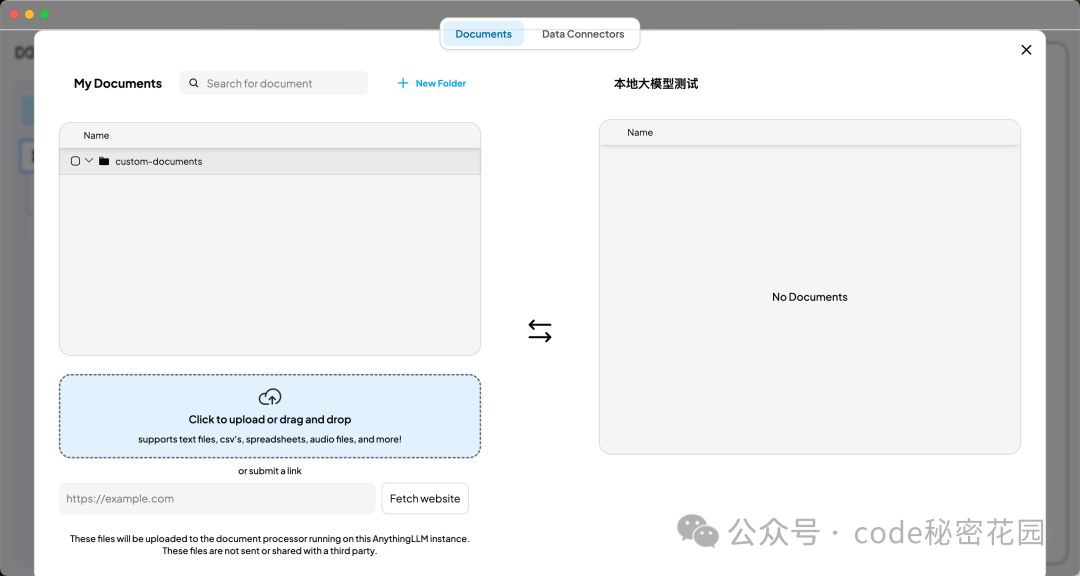
Anything LLM 支持上传多种类型的文件,包括常见的文本文件(如 TXT、Markdown)、文档文件(如 PDF、Word、PPT、Excel)、数据文件(如 CSV、JSON) 等等:
我们把刚才生成的知识库文件上传上去,并且添加到当前工作区,点击保存:
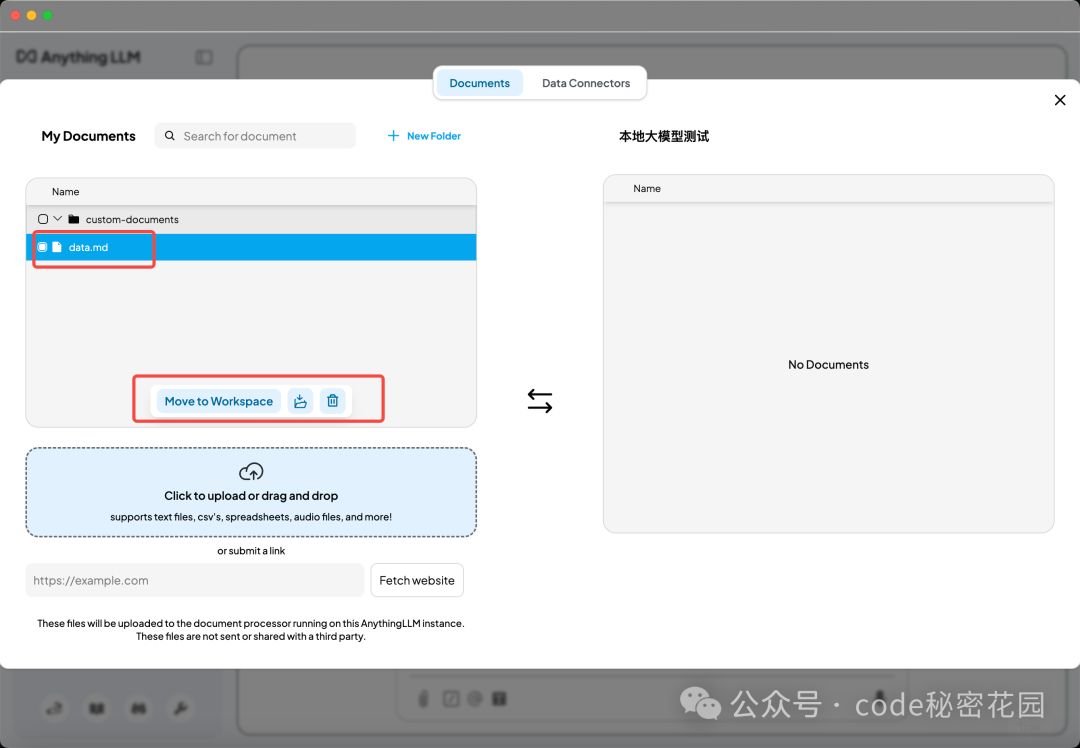
然后我们测试一下,从商品数据里挑选一件商品问一下价格:
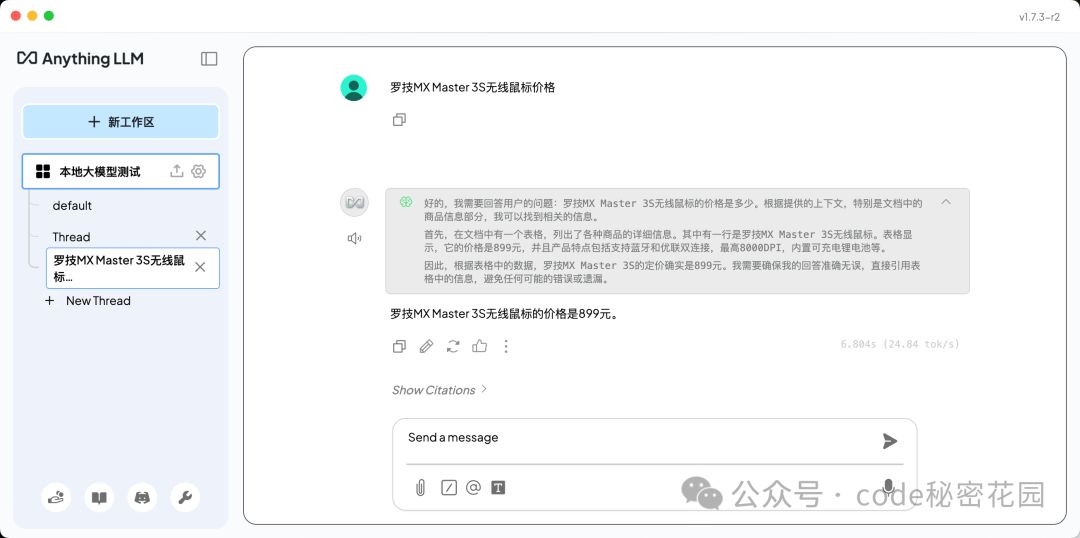
模型精准的回答出了结果,效果还不错。
另外 Anything LLM 还支持直接贴网页链接来构建知识库,我们尝试贴一个 Vue 的文档进去:
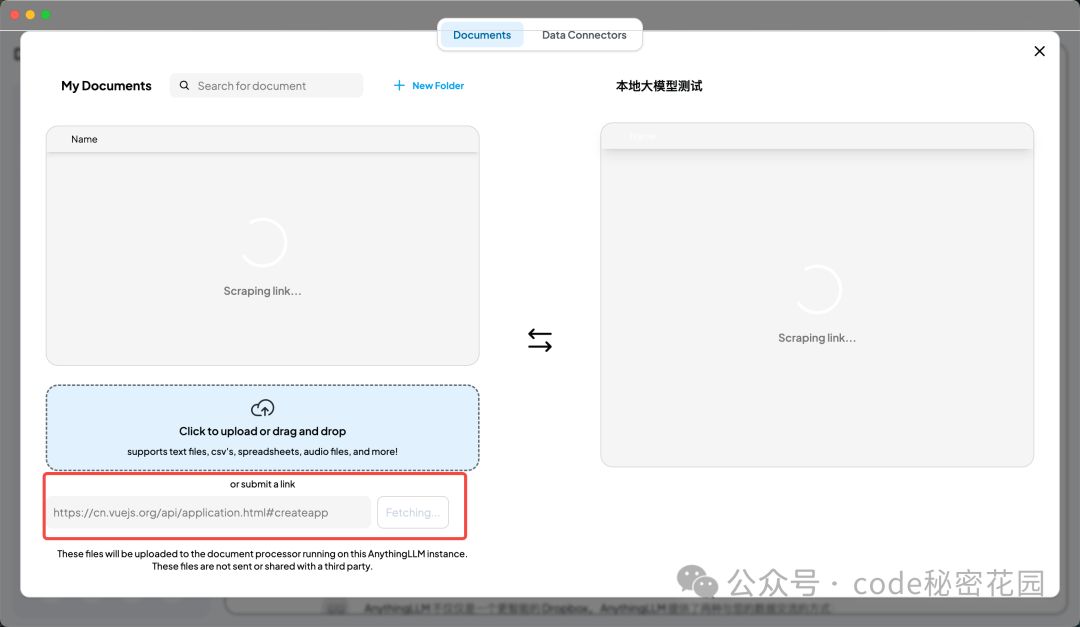
效果也是可以的:
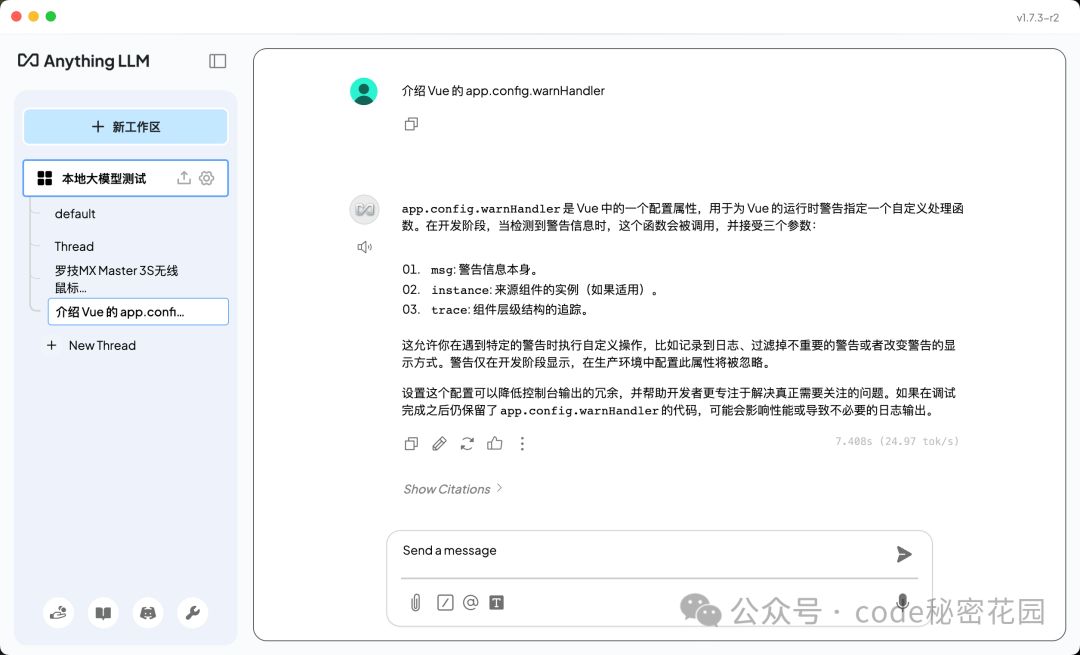
不过网页一般都属于非结构化的数据,不利于模型检索,推荐还是先在本地处理成 AI 友好的格式再上传,效果更好。
Anything LLM 也可以联网
另外, Anything LLM 本身还提供了非常强大的 Agent 能力,例如网页深度抓取、生成图表、链接 SQL 数据库、等等。
当然也支持 Web 搜索的 Agent,测试的话推荐大家选 SearXNG 和 DuckDuckGo 两个免费的搜索引擎,当然效果不如付费的 Google、Bing 的要好。
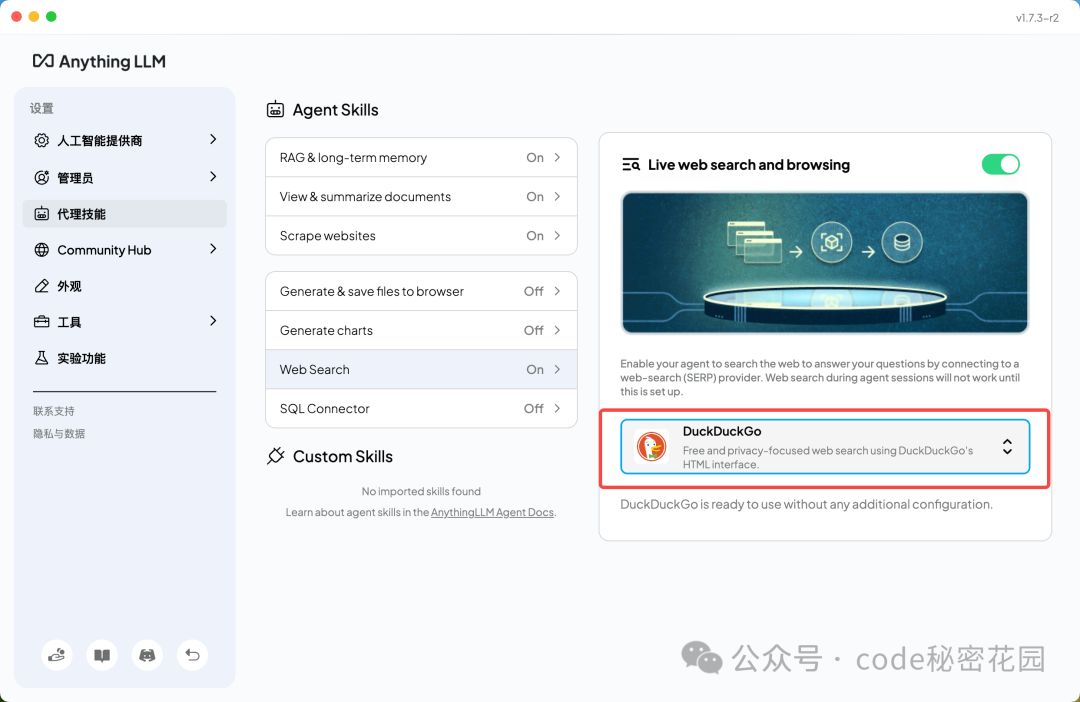
下面我们测试一下,在聊天区打出 @ 就可以调起 agent:
测试结果:
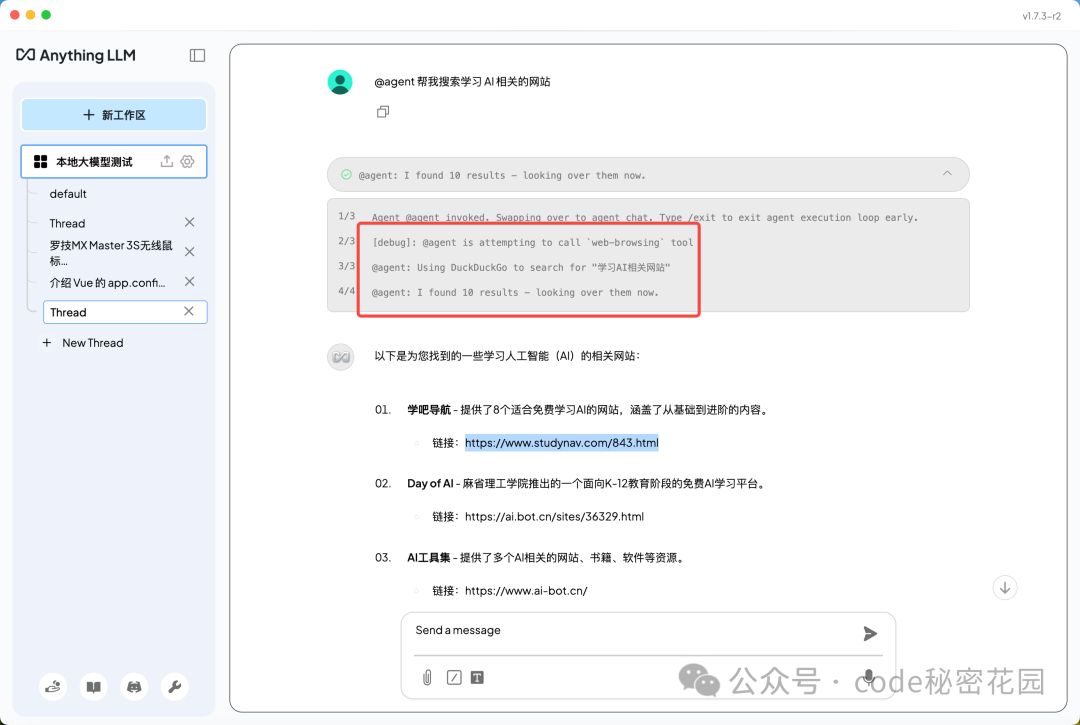
现在,你拥有了一个带本地知识库的本地大模型,完全不用担心信息泄漏、卡顿、付费等问题。
Anything LLM 的 API 调用
但是,在客户端下使用还是太局限了,Anything LLM 还提供了 API 调用的能力,这样我们就可以通过代码来灵活定制我们的使用场景,可以做很多事情,比如:私人知识管理工具、企业内部智能客服等等。
在开始 API 调用之前,我们先要明确 Anything LLM 的两个核心概念:
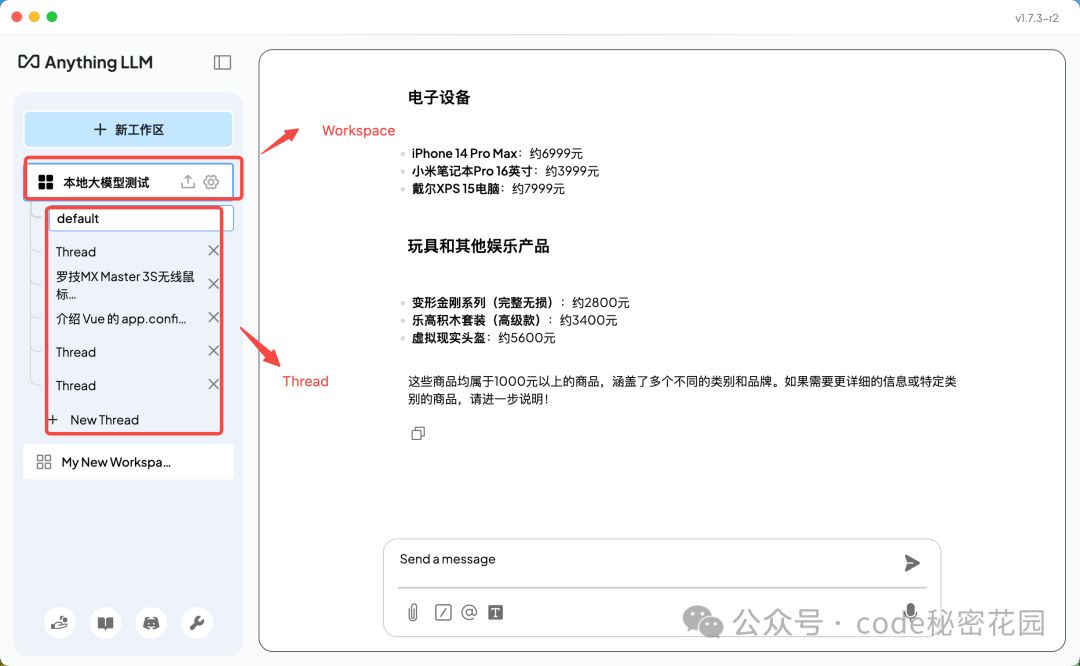
- Workspace:一个独立的环境,用于存储和管理与特定主题或项目相关的文件和数据。用户可以在工作区中上传文件、配置参数,并与模型进行交互。每个工作区的数据是独立的,互不干扰,方便用户对不同主题或项目进行分类管理。
- Thread:工作区中的一次具体对话记录,代表用户与模型之间的一系列交互。它会记录用户的问题和模型的回答,保持对话的连贯性。用户可以在一个工作区中创建多个线程,分别处理不同的问题或任务,方便管理和追溯每次对话的内容。
我们可以在设置 - 工具 - API 密钥下创建 API 密钥,并且查看 Anything LLM 提供的 API 文档:
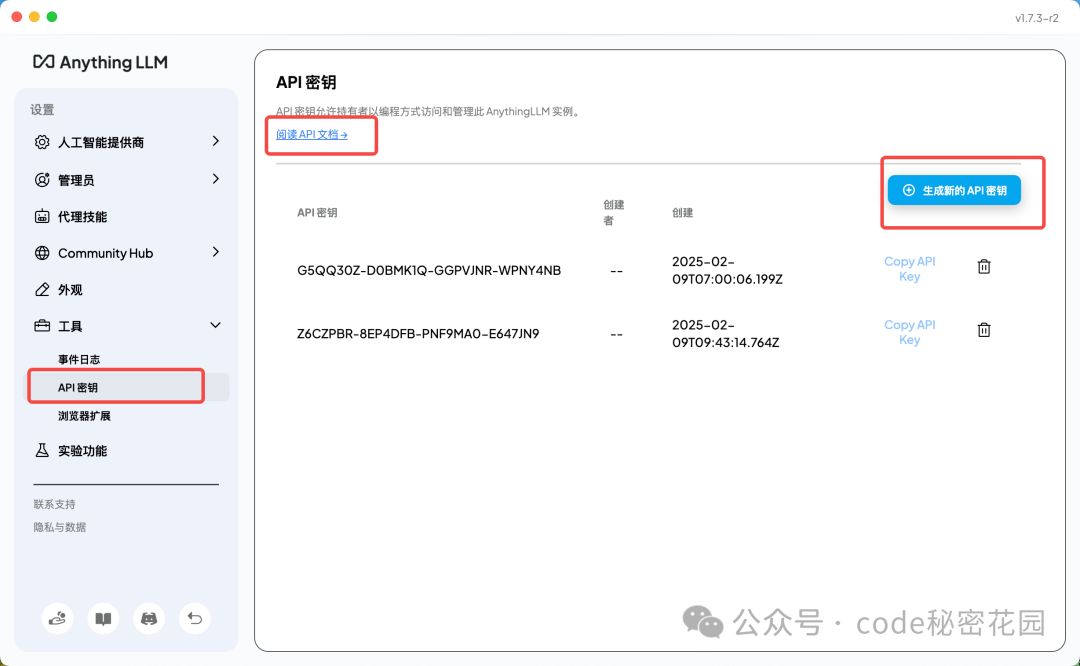
可以看到, Anything LLM 提了非常详细的 API,基本上客户端内能做的事情都能使用 API 调用,包括各种设置、知识库上传、与大模型交互等等 ,点开每个 API 可以看到具体的参数详情,也可以直接测试调用:
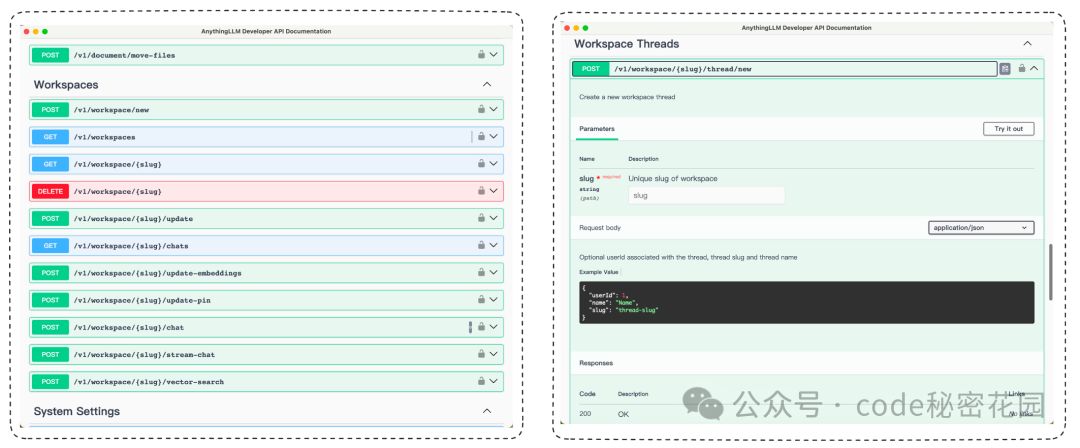
最常用的当然就是和大模型聊天的接口,因为 Anything LLM 中与大模型的交互都发生在 Workspace 下的 Thread 中:
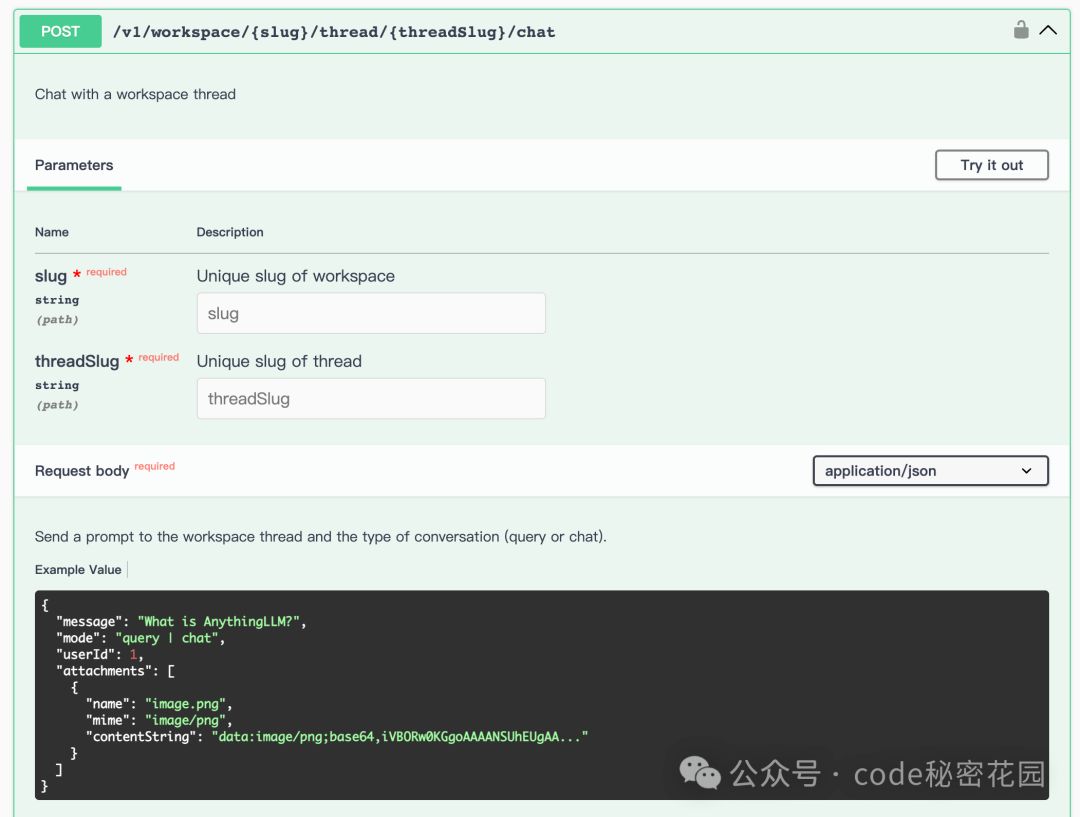
我们看到关键的两个参数是 slug 和 threadSlug ,其实这两个参数就分别代表 Workspace 和 Thread 的唯一标识,在客户端我们是看不到这两个标识的,我们可以通过接口创建新的 Workspace 和 Thread 来获取,或者通过接口查询已有的 Workspace 和 Thread 的 slug:
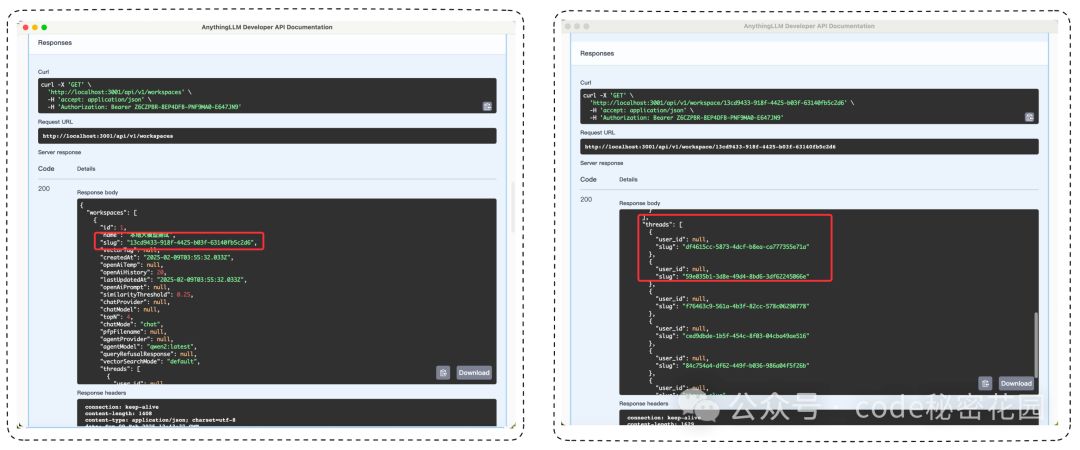
Anything LLM 在本地启动的端口默认是 3001 ,这样我们就凑够了所有关键参数:apiToken、slug 和 threadSlug,我们写个 Node.js 的脚本来测试一下:
import axios from 'axios';
class AnythingLLMClient {
constructor(config) {
this.baseURL = config.baseURL || 'http://localhost:3001';
this.apiToken = config.apiToken;
this.workspaceId = config.workspaceId;
this.threadId = config.threadId;
this.userId = config.userId || 1;
// 创建 axios 实例
this.axiosInstance = axios.create({
baseURL: this.baseURL,
headers: {
'accept': 'application/json',
'Authorization': `Bearer ${this.apiToken}`,
'Content-Type': 'application/json'
}
});
}
async chat(message) {
try {
const url = `/api/v1/workspace/${this.workspaceId}/thread/${this.threadId}/chat`;
const response = await this.axiosInstance.post(url, {
message: message,
mode: 'chat',
userId: this.userId
});
return response.data;
} catch (error) {
console.error('请求错误:', error.message);
}
}
}
async function main() {
try {
// 初始化 AnythingLLM 客户端
const client = new AnythingLLMClient({
baseURL: 'http://127.0.0.1:3001',
apiToken: 'Z6CZPBR-8EP4DFB-PNF9MA0-E647JN9',
workspaceId: '13cd9433-918f-4425-b03f-63140fb5c2d6',
threadId: 'df4615cc-5873-4dcf-b8ea-ca777355e71a',
userId: 1
});
// 发送消息
console.log('发送问题中...');
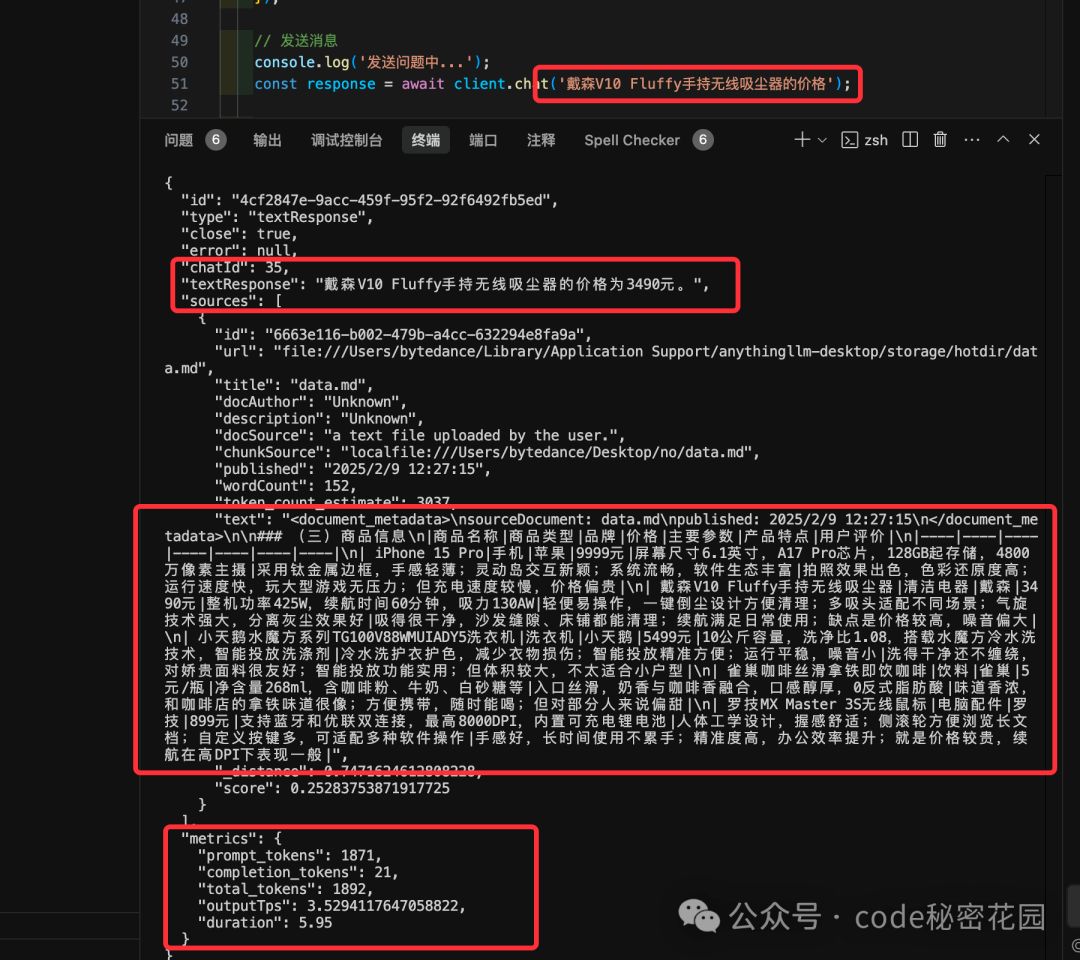
const response = await client.chat('戴森V10 Fluffy手持无线吸尘器的价格');
console.log('\n回答:');
console.log(JSON.stringify(response, null, 2));
} catch (error) {
console.error('发生错误:', error.message);
}
}
// 运行示例
main();我们可以看到返回值中包含模型的回答、本地知识库的检索结果、以及 token 使用、性能等详细数据:
接下来大家就可以随意发挥了…
最后
今天我们讲的大多数都是工具的使用,虽然能力都具备了,定制的灵活性还是差点意思。如果你编程能力过硬的话,完全可以自己写代码通过本地大模型构建复杂的 Agent 或 Workflow,本来想一篇文章讲完的,受限于篇幅原因今天的文章就省略这部分了,下篇文章我们再继续深入。
抖音前端架构团队目前放出不少新的 HC ,有看机会的小伙伴可以看看这篇文章:抖音前端架构团队正在寻找人才!FE/Client/Server/QA,25 届校招同学可以直接用内推码:DRZUM5Z,或者加我微信联系。
如果你想加入高质量前端交流群,或者你有任何其他事情想和我交流也可以添加我的个人微信 ConardLi 。
点赞、转发、小心心 是最大的支持 ⬇️❤️⬇️